
LLM(Large Language Model, 대규모 언어 모델)은 방대한 텍스트 데이터로 사전 학습된 딥러닝 모델이다. 챗GPT(ChatGPT), 클로드(Claude), 제미나이(Gemini), HyperCLOVA X가 모두 LLM이며, 구글 AI Overview와 퍼플렉시티(Perplexity)도 LLM 기반으로 답변을 생성한다.
챗GPT를 처음 써봤을 때 "이건 그냥 검색이랑 다른데"라고 느꼈다면, 직감이 맞습니다. 검색엔진은 인덱싱된 페이지를 찾아 링크로 보여주지만, 챗GPT는 질문의 의미를 이해하고 직접 답변을 생성합니다. 이 차이의 핵심이 LLM이에요.
요약
- LLM = 트랜스포머 구조 + 방대한 텍스트 사전 학습
- 챗GPT, 클로드, 제미나이, HyperCLOVA X가 모두 LLM
- GPT는 LLM의 한 종류 (OpenAI가 만든 특정 모델 계열)
- 구글 AI Overview, 퍼플렉시티도 LLM이 답변을 합성(로스쿨 LLM(법학 석사)과는 완전히 다른 개념)
텍스트를 예측하는 기계가 어떻게 '대화'가 됐을까
2022년 말 챗GPT가 공개된 첫 주, 가장 많이 받은 질문이 "GPT랑 LLM이 뭐가 달라요?"였습니다. 당연히 헷갈릴 수 있습니다. 대학교 시절 저희도 수업에 나올만큼 생소한 개념이었거든요. 결론부터 말하면, LLM은 범주이고 GPT는 그 안의 한 모델 계열입니다.
LLM의 핵심 원리는 "다음 단어 예측"입니다. 수천억 개의 텍스트 조각에서 어떤 단어 다음에 어떤 단어가 오는지 패턴을 학습한 겁니다. GPT-3 기준으로 약 570GB 텍스트(원시 크롤 45TB에서 정제)를 학습했고, 메타의 Llama 3 405B는 15.6조 개 토큰을 썼습니다.
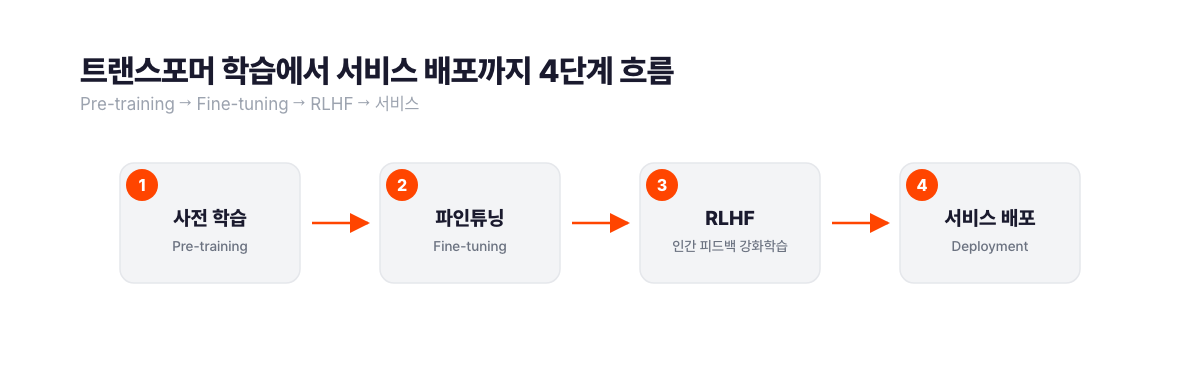
이 규모의 학습을 가능하게 한 게 트랜스포머(Transformer) 구조입니다. 2017년 구글이 발표한 아키텍처로, 문장의 모든 단어를 동시에 보면서 상호 관계를 계산합니다. "어제 내가 서울에서 먹은 것"이라는 문장에서 "것"이 "서울", "어제", "먹은"과 동시에 연결된다는 걸 포착합니다. 이걸 셀프 어텐션(self-attention)이라고 부릅니다.
사전 학습(pre-training)이 끝나면 특정 목적에 맞게 파인튜닝(fine-tuning)합니다. 챗GPT가 대화 상대처럼 작동하는 건 사전 학습 후 사람 피드백 기반 강화학습(RLHF)을 적용했기 때문입니다. GPT-4 사전 학습 비용은 SemiAnalysis 추정 약 1억 달러(1,300억 원) 수준이에요. 한번 학습한 모델을 여러 서비스가 파인튜닝해서 쓰는 이유가 비용에 있습니다.
GPT는 LLM의 한 종류다
흔히 헷갈리는 부분입니다. 칼 종류에 요리용 칼, 과도, 회칼이 있는 것처럼 LLM이 상위 개념이고, GPT는 그 안의 한 계열입니다. OpenAI가 만든 LLM 계열의 이름이에요. 한국형 LLM도 별도로 개발 중입니다. 네이버의 HyperCLOVA X는 한국어 특화 데이터로 학습해서 일반 LLM 대비 한국어 맥락 이해가 높고, LG AI Research의 EXAONE은 일부 오픈소스로 공개되어 기업 자체 서버에 배포하는 사례도 있습니다.
| 모델 | 개발사 | 서비스 | 특징 |
|---|---|---|---|
| GPT-4o | OpenAI | 챗GPT | 멀티모달, 음성·이미지 처리 |
| Claude 3.7 | Anthropic | 클로드 | 긴 컨텍스트 처리, 안전성 강조 |
| Gemini 2.0 | 제미나이 | 구글 서비스 연동, 검색 통합 | |
| HyperCLOVA X | 네이버 | 클로바X, CLOVA Note | 한국어 특화, 네이버 생태계 |
| EXAONE 3.0 | LG AI Research | API 제공 | 한국어·영어 이중언어, 오픈소스 일부 공개 |
| VARCO LLM | NC Soft | B2B 서비스 | 엔터테인먼트·게임 특화 |
LLM은 자신 있게 틀린다
LLM은 "다음 단어 예측" 구조이기 때문에 사실을 모른다고 멈추지 않습니다. 그럴듯한 거짓말을 자신 있게 합니다. 이걸 할루시네이션(hallucination)이라고 해요.
실제 패턴을 보면, 특정 인물의 수상 이력이나 기업 재무 수치처럼 정확한 숫자가 필요한 질문에서 할루시네이션 비율이 높습니다. 실제로 서치폴라리스 팀이 챗GPT에 국내 특정 중소기업 대표자 이름을 물었을 때, 틀린 이름을 완전한 문장으로 확신하며 반환한 사례가 있습니다. 법률·의료·금융에서 LLM을 단독 판단 도구로 쓰면 안 되는 이유입니다.
학습 데이터에 내재된 편향도 문제입니다. 영미권 텍스트 비중이 높은 LLM은 한국 법·문화·시장 맥락을 잘못 이해하는 경우가 있습니다.
이런 경우엔 LLM 단독 판단을 권장하지 않습니다: 의료 처방·법률 해석·금융 규제 해석처럼 오류 비용이 높은 의사결정, 2023년 이후 발생한 실시간 사건 정보 조회, 특정 인물의 수상·학력·이력 확인.
크기가 전부가 아니다: LLM vs SLM
SLM(Small Language Model, 소형 언어 모델)이 최근 주목받는 건 단순히 "작아서"가 아닙니다. 마이크로소프트의 Phi-3-mini(3.8B 파라미터)는 2024년 GPT-3.5 수준의 벤치마크를 4GB RAM 스마트폰에서 돌릴 수 있다고 발표했습니다. 애플은 iOS 18부터 온디바이스 SLM을 탑재해 시리 응답에 사용하고 있어요.
| 구분 | LLM 예시 | SLM 예시 |
|---|---|---|
| 파라미터 | GPT-4: 수천억 개(추정) | Phi-3-mini: 38억 개 |
| 실행 환경 | 대형 GPU 서버 | 스마트폰·노트북 |
| API 비용 | GPT-4o $5/1M tokens {{VERIFY: 2026-04 기준 가격}} | 로컬 실행 시 0원 |
| 응답 속도 | 클라우드 레이턴시 | 로컬 실시간 |
| 프라이버시 | 데이터가 서버로 전송 | 온디바이스 처리 |
| 적합 용도 | 복잡한 추론, 창의적 생성 | 요약·분류·감성 분석 |
이메일 분류처럼 반복적인 작업에 GPT-4o를 쓰면 월 API 비용이 불필요하게 높아집니다. 서치폴라리스가 고객사 자동화 워크플로우를 설계할 때 LLM과 SLM을 나눠 배치하는 이유입니다.

AI 검색에서 LLM이 하는 일
구글 AI Overview, 퍼플렉시티(Perplexity), 챗GPT 검색, 네이버 AI 브리핑이 모두 LLM 기반입니다. 구조는 비슷하지만 방식이 다릅니다. 구글 AI Overview는 구글 인덱스에 이미 있는 문서에서 인용하고, 퍼플렉시티는 답변 시점에 실시간 크롤을 합니다. 챗GPT 검색은 Bing API를 경유해 웹 결과를 받고, 네이버 AI 브리핑은 네이버 블로그·카페 등 UGC 비중이 높습니다. 사용자 질문을 이해하고 콘텐츠를 검색한 후 LLM이 답변을 합성한다는 흐름은 같아요.
중요한 건 LLM이 인용할 출처를 선택한다는 점입니다. 어떤 페이지의 어떤 문장을 인용할지는 LLM이 신뢰할 수 있다고 판단하는 콘텐츠가 선정됩니다. 이 구조에서 콘텐츠가 인용되도록 최적화하는 것이 GEO(생성형 엔진 최적화)이고, 질문-답변 구조에 특화된 최적화를 AEO(Answer Engine Optimization)라고 합니다.
서치폴라리스는 실제 LLM 쿼리 실험을 통해 챗GPT, 퍼플렉시티에 인용되는 콘텐츠 구조를 측정하고 있습니다. 단순 키워드 포함보다 LLM이 500토큰 청크 단위로 읽는 방식에 맞게 정보를 구조화하는 게 핵심입니다. 더 자세한 내용은 AI 검색 최적화 가이드를 참고하세요.
자주 묻는 질문
LLM과 생성형 AI는 같은 개념인가요? 생성형 AI가 더 넓은 개념입니다. LLM은 텍스트 생성에 특화된 생성형 AI의 한 유형이고, 이미지를 생성하는 Stable Diffusion이나 음악 생성 AI는 LLM이 아닙니다.
파라미터가 많을수록 더 좋은 LLM인가요? 항상 그렇지는 않습니다. 학습 데이터의 질, 파인튜닝 방법, 특정 언어·분야 특화 여부가 실제 성능에 더 큰 영향을 미칩니다. 1000억 파라미터 모델이 100억 파라미터 한국어 특화 모델보다 한국어 성능이 떨어지는 경우도 있습니다.
오픈소스 LLM을 기업이 자체 서버에서 운영할 수 있나요? 가능합니다. 메타의 Llama 3 시리즈, LG AI의 EXAONE, 미스트랄(Mistral) 등은 기업 라이선스로 자체 배포가 허용됩니다. 다만 GPU 서버 비용이 발생하고, 보안 패치는 직접 관리해야 합니다.
LLM을 이용해 사내 데이터를 학습시킬 수 있나요? 사전 학습(pre-training)은 비용이 수천만~수억 달러에 달해 현실적으로 어렵습니다. 대신 RAG(Retrieval-Augmented Generation)를 통해 기존 LLM에 사내 데이터를 검색·연결하거나, 파인튜닝으로 특정 작업에 특화시키는 방식이 현실적입니다.
ChatGPT는 LLM인가요? 맞습니다. 챗GPT는 OpenAI의 GPT 계열 LLM을 기반으로 한 대화형 AI 서비스입니다. GPT-4o, GPT-4.5 등의 모델이 내부에서 작동합니다.
LLM과 GPT는 어떻게 다른가요? GPT는 OpenAI가 만든 LLM의 한 종류예요. LLM이 대규모 언어 모델 전체를 가리키는 범주라면, GPT는 그 안에 속하는 특정 모델 계열입니다. 클로드, 제미나이, HyperCLOVA X도 모두 LLM이지만 GPT는 아닙니다.
AI의 3대 요소는 무엇인가요? 데이터, 알고리즘(모델), 컴퓨팅 파워입니다. LLM은 세 요소를 모두 극단까지 밀어붙인 결과물이에요. 방대한 텍스트 데이터를 트랜스포머 구조로 학습하고, 수천 개의 GPU로 수개월을 돌려야 완성됩니다.


