
RAG(Retrieval-Augmented Generation, 검색 증강 생성)는 LLM이 외부 데이터베이스를 실시간 검색해 최신 정보로 답변을 생성하는 기술이다. 파인튜닝과 달리 모델 재학습 없이 적용되며, 챗GPT·퍼플렉시티가 웹 콘텐츠를 인용하는 핵심 구조다.
RAG를 한 문장으로 설명하면 "오픈북 시험"입니다. 일반 LLM은 학습 데이터만으로 답변해요. 시험 전날 암기한 것만 씁니다. RAG는 다릅니다. 답변 전에 외부 데이터베이스를 검색하고, 찾은 내용을 프롬프트에 더해서 답변을 만들어요. 교과서를 꺼내 보면서 시험을 치는 것이죠.
RAG 발음은 "래그"입니다. 영어 단어 rag(헝겊 조각)와 같은 발음이에요. 국내에서는 "알에이지"로 읽는 분이 많지만, 국제 표준은 단어처럼 "래그"입니다.
요약
- Retrieval-Augmented Generation = 검색(R) + 증강(A) + 생성(G)
- LLM 학습 데이터는 특정 시점에 끊긴다. RAG로 최신 정보·비공개 문서를 실시간 반영
- 모델을 재학습하지 않아도 된다. 파인튜닝보다 비용이 낮고 속도가 빠르다
- 챗GPT·퍼플렉시티가 특정 페이지를 인용하는 구조 자체가 RAG 기반이다
할루시네이션이 줄어드는 이유
LLM에는 구조적 한계가 있습니다. 학습 데이터가 특정 시점에 끊기고, 그 이후 정보는 모릅니다. 모르면 지어냅니다. 이게 할루시네이션(hallucination)이에요.
RAG는 이 문제를 우회합니다. 답변을 생성하기 전에 외부 데이터베이스에서 관련 문서를 가져옵니다. LLM은 그 문서를 근거로 답변을 만들어요. 정보를 기억하는 게 아니라 찾아서 쓰는 구조이기 때문입니다.
물론 한계는 있습니다. 지식 베이스 자체가 잘못 구성되어 있으면 RAG도 잘못된 정보를 가져옵니다. Garbage in, garbage out. RAG는 할루시네이션을 줄이는 구조이지, 완전히 없애는 마법이 아니에요.
RAG가 작동하는 세 단계
각 단계마다 병목이 다릅니다. 어디서 막히느냐가 구현 품질을 결정해요.
Retrieval (검색)
사용자 질문을 벡터로 변환해 지식 베이스에서 유사한 문서를 검색합니다. 검색 품질이 전체 파이프라인의 상한선을 결정해요.
Augmentation (증강)
찾은 문서를 LLM 프롬프트에 추가합니다. "이 문서를 참고해서 답해줘"라고 컨텍스트를 주는 것이에요.
Generation (생성)
LLM이 증강된 프롬프트로 답변을 생성합니다. 파운데이션 모델은 건드리지 않아요.
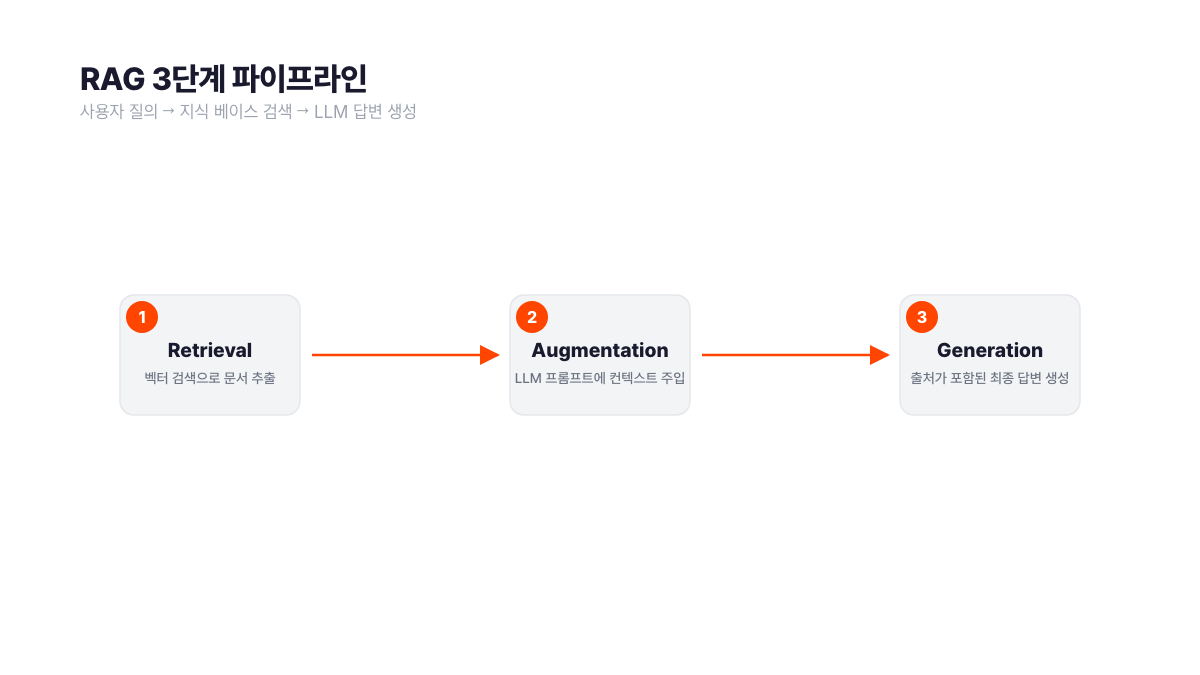
핵심은 2단계입니다. 파운데이션 모델 자체는 건드리지 않아요. 모델을 재학습하지 않고도 새로운 도메인 지식을 실시간으로 주입할 수 있습니다. 이게 RAG가 기업에서 빠르게 채택된 이유입니다.
2020년 Facebook AI Research(현 Meta AI)가 처음 발표한 RAG 논문(Lewis et al.) 에서 제안된 이 구조는, 이후 기업용 AI 애플리케이션의 사실상 표준이 됐습니다.
RAG vs 파인튜닝, 뭐가 다른가
파인튜닝은 모델 자체를 바꾸고, RAG는 모델 밖에서 정보를 밀어 넣습니다. 출발점이 다릅니다.
| 항목 | RAG | 파인튜닝(Fine-tuning) |
|---|---|---|
| 작동 방식 | 외부 DB를 실시간 검색해 프롬프트에 추가 | 모델 가중치를 도메인 데이터로 재학습 |
| 최신 정보 반영 | DB 업데이트만 하면 즉시 반영 | 재학습 필요 (시간·비용 소모) |
| 비용(10만 건 문서 기준) | 벡터 DB 운영비 월 $70~150 수준 | GPT-3.5급 파인튜닝 1회 $200~400 |
| 적합한 상황 | 최신 정보·내부 문서 기반 챗봇 | 특정 문체·도메인 스타일 습득 |
| 할루시네이션 | 출처가 있어 상대적으로 낮음 | 여전히 발생 가능 |
| 적용 속도 | 빠름 (지식 베이스 구축이 핵심) | 느림 (학습 파이프라인 필요) |
RAG를 먼저 써야 할 때는 내부 문서나 최신 뉴스 기반으로 챗봇이 답변해야 하는 경우입니다. 파인튜닝이 더 나은 경우는 의학·법률처럼 모델의 추론 방식 자체를 도메인에 맞게 바꿔야 할 때에요. 많은 팀이 RAG로 먼저 프로토타입을 만들고, 필요할 때 파인튜닝을 추가합니다.
마케터가 RAG를 알아야 하는 이유
기술 블로그와 다른 지점입니다.
챗GPT·퍼플렉시티 같은 AI 검색 엔진이 특정 웹페이지를 인용하는 구조가 RAG 기반입니다. AI가 질문을 받으면, 웹을 검색하고(Retrieval), 관련 콘텐츠를 가져와서(Augmentation), 답변을 만들어요(Generation). 결국 AI가 어떤 콘텐츠를 "가져올 것인가"가 GEO(Generative Engine Optimization)의 핵심 질문이 됩니다.
서치폴라리스가 고객사 GEO 진단을 할 때 가장 먼저 확인하는 건 이 질문입니다. "AI가 이 브랜드의 콘텐츠를 RAG로 가져갈 이유가 있는가?" RAG 파이프라인이 콘텐츠를 선택하는 기준과, GEO 최적화 전략이 향하는 방향이 일치하기 때문이에요.
RAG가 콘텐츠를 선택할 때 주로 보는 건 두 가지입니다. 의미론적 유사성(사용자 질문과 콘텐츠 벡터가 얼마나 가까운가)과 신뢰성 지표(링크·인용·E-E-A-T 시그널)입니다. AI 검색 최적화 전략이 이 두 축을 높이는 방향으로 설계되는 이유가 여기에 있어요.
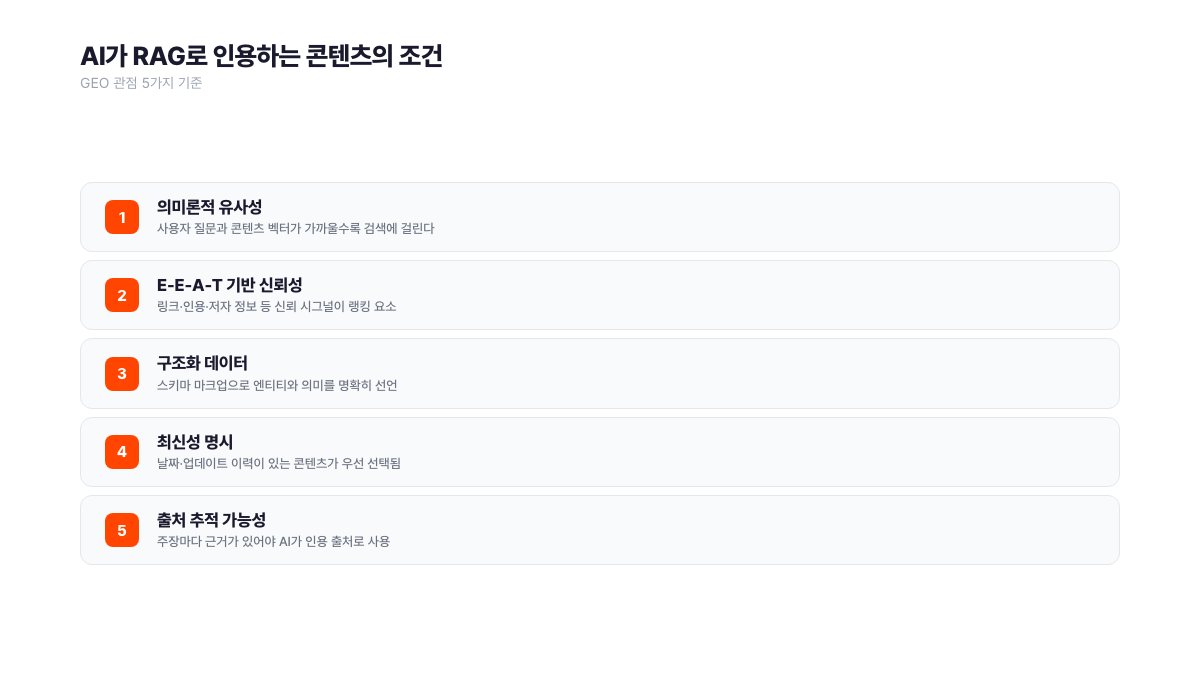
RAG가 맞지 않는 경우
RAG를 쓰면 안 되는 상황이 있습니다.
지식 베이스가 정리되지 않은 상태에서 RAG를 붙이면 오히려 엉뚱한 문서를 가져와 할루시네이션이 더 심해질 수 있어요. 또 모델의 추론 방식 자체를 바꿔야 하는 경우(예: 특정 언어 스타일, 전문 도메인 추론)에는 파인튜닝이 더 적합합니다. "RAG를 쓰면 다 해결된다"는 과장이에요.
아직 해결되지 않은 문제가 있습니다. 멀티홉 질문(예: "A의 CEO가 다니던 회사의 투자자가 운영하는 다른 회사는?")에서는 단일 검색으로 필요한 문서를 모두 가져오지 못하는 경우가 많아요. 2024년 이후 Self-RAG, HyDE, FLARE 같은 변형 구조가 나온 이유가 여기에 있지만, 표준 해법은 아직 없습니다.
다만 비용 대비 효율성에서는 대부분의 기업 챗봇 첫 번째 선택지가 RAG인 것이 현실이에요.
자주 묻는 질문
RAG는 어떻게 읽나요? 발음이 궁금해요.
"래그"로 읽어요. Retrieval-Augmented Generation의 앞글자를 딴 약어입니다. 영어권에서도 "rag"를 한 단어처럼 발음하며, 헝겊 조각을 뜻하는 영어 rag와 철자가 같지만 전혀 다른 개념이에요.
RAG란 무엇인가요?
LLM이 답변을 생성하기 전에 외부 데이터베이스를 실시간으로 검색해 관련 문서를 프롬프트에 추가하는 기술이다. 모델 자체를 바꾸지 않고 최신 정보를 반영할 수 있어요.
RAG의 구조는 어떻게 되나요?
크게 두 단계예요. 먼저 Retriever가 질문과 가장 가까운 문서를 벡터 검색으로 꺼냅니다. 다음으로 Generator(LLM)가 그 문서를 프롬프트에 붙여 최종 답변을 만들어요. 검색 → 생성, 이 순서가 핵심이에요.
RAG의 단점은 무엇인가요?
검색 품질에 답변 품질이 종속돼요. 관련 문서를 잘못 가져오면 LLM이 아무리 뛰어나도 오답을 냅니다. 벡터 DB 구축 비용, 검색 레이턴시, 청킹 설계 실패도 현장에서 자주 마주치는 문제예요.
RAG와 파인튜닝은 어떻게 다른가요?
파인튜닝은 모델 가중치를 직접 업데이트해 지식을 "학습"시켜요. RAG는 모델을 건드리지 않고 외부 문서를 실시간으로 주입합니다. 최신 정보 반영이 필요하거나 비용이 제한적이면 RAG가 유리해요.
RAG 종류에는 어떤 게 있나요?
대표적으로 Naive RAG, Advanced RAG, Modular RAG 세 가지로 분류해요. Naive는 단순 검색+생성, Advanced는 재순위화·쿼리 재작성 등을 추가, Modular는 검색·생성 모듈을 목적에 맞게 교체할 수 있는 구조예요.
RAG를 실제로 사용하는 서비스 예시가 있나요?
퍼플렉시티가 가장 대표적이에요. 웹을 실시간 검색한 뒤 인용 출처와 함께 답변을 내놓는 구조가 RAG 기반입니다. 챗GPT의 웹 검색 기능, 기업 내부 문서 챗봇도 같은 원리로 작동해요.
GEO 관점에서 RAG가 왜 중요한가요?
퍼플렉시티·챗GPT 같은 AI가 RAG로 가져오는 콘텐츠가 곧 AI 답변의 재료가 됩니다. 내 콘텐츠가 벡터 검색에서 상위로 검색되도록 구조화하는 것, 이게 GEO 전략의 출발점이에요.


