
구조화 데이터(Structured Data)는 웹페이지의 의미를 schema.org 어휘로 기계 판독 가능하게 표시하는 코드 마크업이다. JSON-LD, Microdata, RDFa 세 형식이 있으며 구글은 JSON-LD를 공식 권장한다. 올바르게 적용하면 리치결과(Rich Result) 노출과 AI Overview 인용 가능성이 높아진다. 데이터베이스에서 말하는 '정형 데이터(SQL 테이블, 행·열 정렬 데이터)'와는 완전히 다른 개념이다.
"구조화 데이터 뜻"을 검색하면 이상한 일이 생깁니다.
결과 절반이 AWS, Oracle, integrate.io 글들이에요. SQL 테이블, 비정형 데이터, 데이터웨어하우스 이야기를 합니다. SEO 담당자가 찾는 JSON-LD나 schema.org와 전혀 관계없는 내용이에요.
두 개념이 "Structured Data"라는 같은 영어 단어를 공유하는 탓에 생기는 혼란입니다. 이 글에서는 SEO와 GEO 맥락, 즉 웹마크업으로서의 구조화 데이터만 다뤄요.
요약
- 구조화 데이터(SEO 맥락) = 웹페이지에 삽입하는 schema.org 코드 태그
- 목적: 구글, 네이버, AI 검색엔진이 페이지 의미를 기계 판독
- 형식 3가지: JSON-LD(권장), Microdata, RDFa
- 결과: 리치결과 노출, AI Overview 출처 선택 가능성 향상
- GEO 연결: 구조화 데이터는 LLM이 콘텐츠를 인용할 때 참조하는 엔티티 신호
같은 단어, 전혀 다른 두 개념
데이터베이스 세계에서 "정형 데이터"는 행과 열로 정리된 SQL 테이블 데이터를 말해요. 비정형(이미지, 텍스트, 로그)이나 반정형(JSON, XML) 데이터와 구분하는 빅데이터 용어입니다.
SEO/GEO에서는 달라요. 웹페이지 HTML 안에 삽입하거나 <head> 태그에 추가하는 schema.org 마크업 코드예요. 구글 Search Central이 공식 가이드를 운영하고, 네이버 서치어드바이저도 별도 구조화 데이터 가이드를 제공합니다.
쉬운 비유가 있어요. 식당에서 메뉴판에 붙이는 알레르기 표기 스티커예요. 음식 자체가 바뀌는 게 아닙니다. 웨이터(검색엔진)가 주방(서버)에 가기 전에 손님(사용자)에게 핵심 정보를 전달하는 레이블이에요.
구글은 이 레이블을 읽어서 "이 페이지는 FAQ입니다", "이 페이지는 제품입니다", "이 기사는 특정 날짜에 발행됐습니다"를 파악해요. 파악이 정확할수록 리치결과(별점, 가격, FAQ 드롭다운, 이벤트 날짜 등)로 노출될 가능성이 높아집니다.
JSON-LD, Microdata, RDFa: 현실적 선택
세 방식 모두 schema.org 어휘를 사용하지만 삽입 방법이 달라요.
| 방식 | 삽입 위치 | 구글 권장 | 선택 기준 |
|---|---|---|---|
| JSON-LD | <script> 태그 (주로 <head>) | ✅ 공식 권장 | 신규 구현 시 기본 선택 |
| Microdata | HTML 요소 속성에 직접 삽입 | 지원 | 레거시 시스템 유지 시 |
| RDFa | HTML 요소 속성에 직접 삽입 | 지원 | Linked Data·시맨틱 웹 연구 목적 |
JSON-LD를 선택하는 이유는 단순해요. HTML 콘텐츠와 분리돼 있어서 개발자가 수정하기 쉽고, WordPress, Ghost, Shopify 등 주요 CMS에서 플러그인으로 빠르게 추가할 수 있습니다.
Microdata와 RDFa는 HTML 요소에 속성을 직접 추가하는 방식이에요. 콘텐츠 수정마다 마크업도 함께 관리해야 합니다. 새로 시작하는 경우라면 JSON-LD가 맞는 선택이에요.
FAQPage 마크업을 예시로 보면 구조가 명확해집니다.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "구조화 데이터란?",
"acceptedAnswer": {
"@type": "Answer",
"text": "웹페이지에 삽입해 검색엔진이 의미를 기계 판독하도록 돕는 schema.org 기반 코드 마크업입니다."
}
}]
}
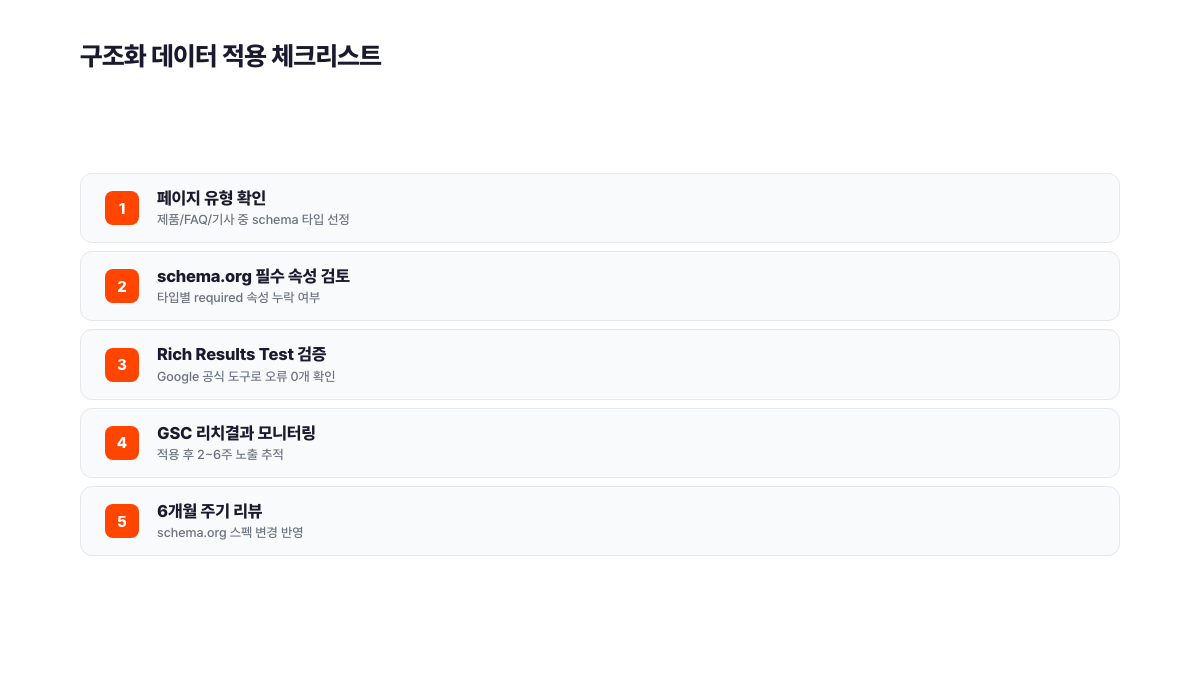
적용 후 구글 Rich Results Test에서 즉시 유효성을 검증할 수 있어요.
CMS별로 구현 방법이 달라요. WordPress에서는 Yoast SEO와 Rank Math 플러그인이 각각 JSON-LD를 자동 생성합니다. 두 플러그인을 동시에 활성화하면 같은 페이지에 중복 스키마가 출력되면서 Search Console에 오류가 잡혀요. Ghost에서는 에디터 설정 화면의 'Code injection' > <head> 섹션에 직접 삽입합니다.
AI 검색이 구조화 데이터를 읽는 방식
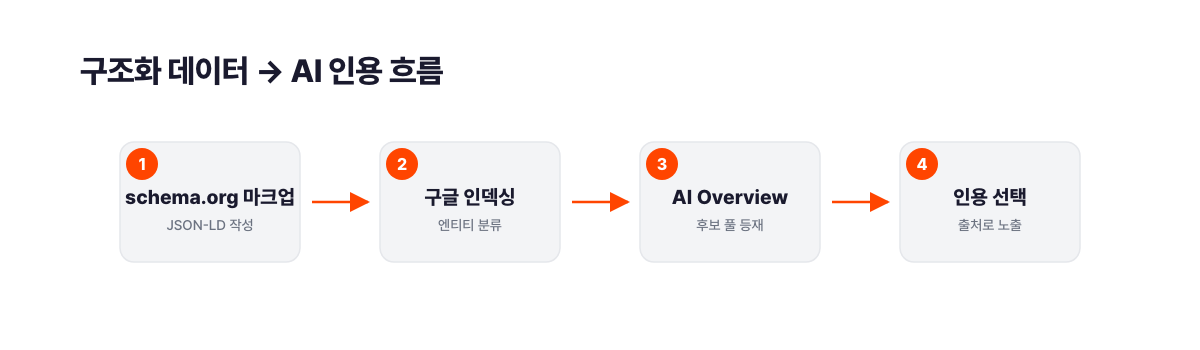
AI Overview(구글 AI 개요)와 챗GPT(ChatGPT), 퍼플렉시티(Perplexity) 같은 AI 검색엔진이 출처를 선택하는 메커니즘에 구조화 데이터가 관여해요.
구글 AI Overview는 기존 검색 인덱스를 바탕으로 작동합니다. 구조화 데이터가 적용된 페이지는 구글이 분류할 때 더 많은 엔티티 신호를 제공해서, 관련 AI Overview가 생성될 때 후보 출처로 선택될 가능성이 높아집니다.
RAG(검색 증강 생성) 파이프라인에서는 문서 메타데이터 역할을 해요. LLM이 외부 문서를 검색해 답변을 생성할 때, 스키마 마크업이 붙은 문서는 엔티티가 명확해서 관련 쿼리에 더 잘 매칭됩니다. 퍼플렉시티와 챗GPT가 Bing과 구글 인덱스를 활용하는 것도 같은 맥락이에요.
서치폴라리스에서 FAQPage 스키마를 적용한 클라이언트 페이지가 퍼플렉시티 "Sources" 섹션에 노출된 사례를 확인했어요. 다만 구조화 데이터 하나로 AI 인용이 보장되는 건 아닙니다. 콘텐츠 자체의 품질과 E-E-A-T 신호가 함께 받쳐줘야 해요.
구조화 데이터가 없는 페이지도 인용됩니다. 그러나 구조화 데이터가 있는 페이지가 인용될 때 AI가 엔티티와 속성을 더 정확하게 파악해요. 답변의 정확도가 높아지고, 출처로 다시 선택될 가능성도 높아집니다.
가장 흔한 실수 세 가지
구조화 데이터 구현에서 반복해서 보이는 패턴이 있어요.
없는 내용에 마크업 추가
별점이 없는 페이지에 aggregateRating을 넣거나, 가격 정보가 없는 페이지에 Product 가격 속성을 추가하는 경우예요. 구글은 이를 스팸 정책 위반으로 분류하고 리치결과 자격을 박탈합니다. 구조화 데이터는 페이지에 실제로 있는 내용만 반영해야 해요.
JSON 문법 오류
쉼표 누락, 중괄호 불일치 같은 기초 오류가 마크업 전체를 무효화해요. 구글 Search Console 리치 리절츠 보고서와 Schema.org Validator에서 정기적으로 확인하는 루틴이 필요합니다.
페이지 유형과 스키마 불일치
Article 스키마를 제품 페이지에 적용하거나 FAQPage 스키마를 FAQ 섹션이 없는 블로그 글에 쓰는 경우예요. 구글은 페이지 콘텐츠와 스키마 유형이 일치하는지 검증합니다. 불일치 시 리치결과를 표시하지 않아요. 구글 Search Central에서 지원하는 리치결과 유형을 먼저 확인하는 게 순서입니다.
2023년 8월, 구글은 FAQPage와 HowTo 리치결과 노출 기준을 바꿨어요. FAQPage는 권위 있는 사이트(주로 정부·의료기관)에만 표시하도록 제한했고, HowTo 리치결과는 데스크톱에서 완전히 제거됐습니다. 구조화 데이터를 올바르게 적용해도 자동으로 리치결과가 보장되는 건 아니에요.
적용 우선순위와 시작점
모든 페이지에 모든 스키마를 한 번에 적용하는 건 비효율적이에요. 구현 난이도 대비 리치결과 획득 가능성을 기준으로, 서치폴라리스는 FAQPage와 Article 마크업부터 시작하는 걸 추천합니다. AI Overview 출처로 선택될 때도 FAQ 형식이 명시된 페이지가 더 유리해요.
제품이나 서비스 페이지가 있다면 Product, Service, LocalBusiness 스키마를 다음 단계로 추가합니다. Organization 스키마는 기업 브랜드 엔티티 신호로, AI 검색 최적화 전략에서 브랜드 인지도를 구축할 때 중요한 역할을 해요.
구조화 데이터와 llms.txt는 다른 레이어를 담당합니다. llms.txt가 AI 크롤러에게 사이트 전체 구조를 안내한다면, 구조화 데이터는 개별 페이지의 의미를 설명해요. 둘 다 적용하면 AI 검색 가시성이 높아집니다.
적용 후 구글 Search Console의 '검색결과 > 리치결과 보고서'에서 상태 변화를 모니터링합니다. 구글이 재크롤하고 리치결과를 표시하기까지 통상 2~6주가 걸려요. 이 기간 동안 GSC에서 오류가 없는지 확인하고, 유효 상태 전환 후 'Search Appearance' 필터로 실제 CTR 변화를 측정하는 게 순서입니다.
구조화 데이터는 GEO(Generative Engine Optimization)의 테크니컬 레이어 중 하나예요. 단독 적용보다 E-E-A-T 신호와 함께 구성할 때 AI 인용 빈도가 달랐습니다. 스키마 코드가 신뢰 가능한 콘텐츠에 붙는 레이블로 기능해야지, 내용 없는 레이블로는 효과가 없어요.
구조화 데이터를 서두를 필요가 없는 경우
월 방문자 100 미만의 신규 사이트라면 구조화 데이터보다 콘텐츠 품질이 먼저예요. 스키마 없이도 권위 있는 콘텐츠는 AI에 인용됩니다. 순서가 있어요. 콘텐츠 → E-E-A-T 구축 → 기술 최적화(구조화 데이터는 이 단계). 역순으로 접근하면 빈 레이블만 남아요.
자주 묻는 질문
구조화 데이터란?
웹페이지의 내용을 검색엔진이 기계적으로 읽을 수 있도록 schema.org 어휘로 표시한 코드 마크업이에요. 단순 텍스트가 아닌 "이 페이지는 레시피입니다", "이 숫자는 별점입니다"처럼 의미를 명시합니다. 리치결과 노출의 전제 조건이에요.
"structured data"는 한국어로 무엇인가요?
구조화 데이터입니다. SEO/GEO 맥락에서는 schema.org 기반의 마크업 코드를 가리켜요. 빅데이터 분야의 정형 데이터(structured data)와 같은 원어를 쓰지만, 검색 최적화에서는 의미가 달라요.
JSON-LD와 Microdata 차이는?
JSON-LD는 HTML 본문과 분리된 script 태그에 작성해 유지보수가 쉬워요. Microdata는 HTML 태그에 직접 속성을 추가하는 방식이라 구조가 복잡해집니다. 구글은 JSON-LD를 공식 권장 형식으로 제시해요.


