
AI Summary
AI 검색 최적화(GEO)는 챗GPT, 퍼플렉시티, 구글 AI 오버뷰가 답변을 생성할 때 내 브랜드를 출처로 쓰게 만드는 작업입니다. 네이버 DataLab에 따르면 한국에서 "GEO" 검색량은 2025년 1월 대비 2026년 3월 약 2.5배 급증해 용어 경쟁에서 압도적 1위가 됐습니다. 핵심은 백링크가 아니라 500토큰 청크 아키텍처, 엔티티 합의, 그리고 엔진별 인용 기준에 맞춘 콘텐츠 구조입니다.
AI 검색 최적화란 무엇인가
AI 검색 최적화는 생성형 AI가 사용자 질문에 답할 때 내 브랜드와 콘텐츠를 출처로 인용하게 만드는 작업입니다. 영문으로는 GEO(Generative Engine Optimization)로 부릅니다. 기존 검색엔진최적화(SEO)가 10개의 파란 링크에 올라가는 게임이었다면, GEO는 한 줄짜리 AI 답변 안에 내 이름이 들어가는 게임입니다.
노출 방식이 근본적으로 바뀌었습니다. 구글 AI 오버뷰는 평균 3~5개 출처만 요약합니다 . 챗GPT 웹 브라우징 모드는 답변 하나에 3~8개 링크만 인용합니다 . 퍼플렉시티는 Answer 블록 상단에 통상 4개 출처만 노출합니다. 구글 상위노출 10위권에 들어도 AI 답변에서는 보이지 않을 수 있습니다.
여기서 중요한 구분이 필요합니다. SEO는 검색엔진 결과 페이지의 링크 순위 경쟁이고, AEO(Answer Engine Optimization)는 Featured Snippet과 PAA 발췌 경쟁이며, GEO는 LLM 답변 생성 과정의 출처 인용 경쟁입니다. 세 개념은 배타적이지 않습니다. GEO가 AEO를 포함하고, AEO가 SEO 위에 얹힌 상위 레이어 구조입니다.

테크니컬 SEO 기본(인덱싱, 크롤링, Core Web Vitals)이 깨져 있으면 AI 엔진 크롤러도 페이지를 못 읽습니다. 그래서 GEO는 SEO의 대체가 아니라 상위 레이어입니다. SEO가 기초 공사라면 GEO는 그 위에 올리는 최상층입니다.
왜 2026년 한국에서 GEO 관심이 높아졌는가?
한국에서 용어 경쟁이 끝났습니다. 네이버 DataLab 기준 2025년 1월부터 2026년 3월까지 15개월간 "GEO", "AEO", "AI 검색 최적화", "생성형 검색 최적화" 4개 용어의 검색량 추이를 비교해보면 뚜렷한 결과가 보입니다.
"GEO"는 2025년 1월 상대 지수 39.8에서 2026년 3월 100으로 약 2.5배 상승했습니다. 같은 기간 "AEO"는 43.7에서 60.4로 완만하게 올랐습니다. "AI 검색 최적화" 한글 풀네임은 2026년 3월 단 한 번 1.03으로 반짝했을 뿐 거의 무명에 가깝습니다. "생성형 검색 최적화"는 15개월 내내 측정값이 없습니다. 한국 검색자들이 실제로 쓰는 용어는 GEO 단어 하나로 귀결됩니다.
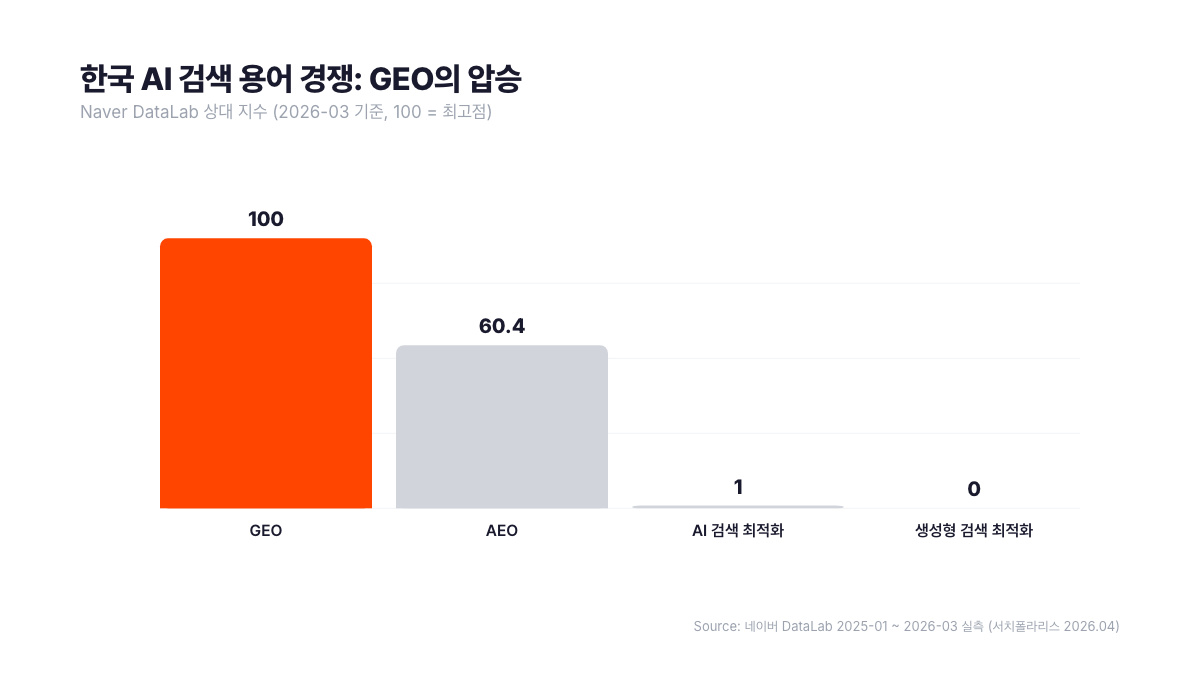
네이버 Search Ad 월간 검색량으로 봐도 결과는 같습니다. GEO는 4,850회, AEO는 2,760회. "AI 검색 최적화" 한글 풀네임은 100회입니다. "생성형 검색 최적화"는 10회를 못 넘겼습니다. GEO와 한글 풀네임 사이 격차가 48배입니다.
문제는 "GEO" 세 글자가 지리(Geography)와 구분이 안 된다는 점입니다. 이 글 제목에 한글을 쓴 이유도 거기에 있습니다. 한국어 검색 의도는 제목이 잡고, 본문에서는 GEO를 주 엔티티로 박습니다.
14만 건 넘는 네이버 블로그 포스트가 "AI 검색 최적화"로 검색됩니다. 대부분 2025년 9월 이후 발행입니다. 반년도 안 된 시장입니다.
챗GPT·퍼플렉시티·구글 AI 오버뷰는 답변을 어떻게 고르는가
엔진마다 인용 선호 기준이 다릅니다. 한 페이지로 여러 엔진을 동시 공략하려면 공통 구조를 만들고 엔진별 차이 지점만 보강해야 합니다.
구글 AI 오버뷰는 기존 구글 서치 랭킹 시그널 위에 답변 요약 레이어를 얹은 구조입니다 . PAA(People Also Ask) 질문과 매칭되는 H2, 최종 확인 날짜, 숫자가 명시된 페이지가 특히 자주 발췌됩니다. 챗GPT 웹 브라우징은 OpenAI-SearchBot이 크롤링한 페이지 중에서 질문 의도와 직접 매칭되는 청크를 우선 인용합니다. 퍼플렉시티는 인용 가능성과 신선도를 가장 엄격하게 봅니다. 출처 링크가 없거나 날짜 마킹이 없는 페이지는 거의 탈락합니다.
| 엔진 | 우선 시그널 | 핵심 최적화 포인트 |
|---|---|---|
| 구글 AI 오버뷰 | 기존 SEO 랭킹 + 신선도 + PAA 매칭 | PAA 질문 기반 H2, 최종 확인 날짜, Article 스키마 |
| 챗GPT (Web Browsing) | 크롤러 접근성 + 청크 독립성 | OpenAI-SearchBot 허용, 500토큰 청크 분리 |
| 퍼플렉시티 | 인용 가능성 + 날짜 + 원본 데이터 | 출처 링크 명시, 날짜 마킹, 1차 데이터 |
| 제미나이(Gemini) | 엔티티 연결 + 멀티모달 | 이미지 alt, 테이블, Organization 스키마 |
| 네이버 Cue: | 네이버 생태계 권위 + 한국어 적합성 | 네이버 블로그·뉴스 교차 배포, 한글 엔티티 |
| 클로드(Claude) Projects | 문서 구조화 + 팩트 정확성 | 명확한 H2 계층, 근거 링크, 정량적 표현 |
네이버 Cue:와 HyperCLOVA X는 도메인 권위를 한국 기관·언론사 인용에 강하게 의존합니다. 영문 GEO 가이드를 그대로 번역하면 네이버 계열 엔진에서는 노출이 잘 되지 않습니다. 한국어 공식 명칭, 한글 고유명사, 한국 언론 교차 인용이 별도로 필요합니다.
한 가지 더 중요한 게 있습니다. 모든 엔진이 공통으로 "이 페이지 하나만 읽어도 답이 되는가"를 봅니다. 청크 단위로 독립 답변이 성립해야 추출됩니다. 이게 500토큰 청크 아키텍처가 GEO의 기술적 핵심인 이유입니다.
500토큰 청크 아키텍처가 왜 GEO의 엔진인가
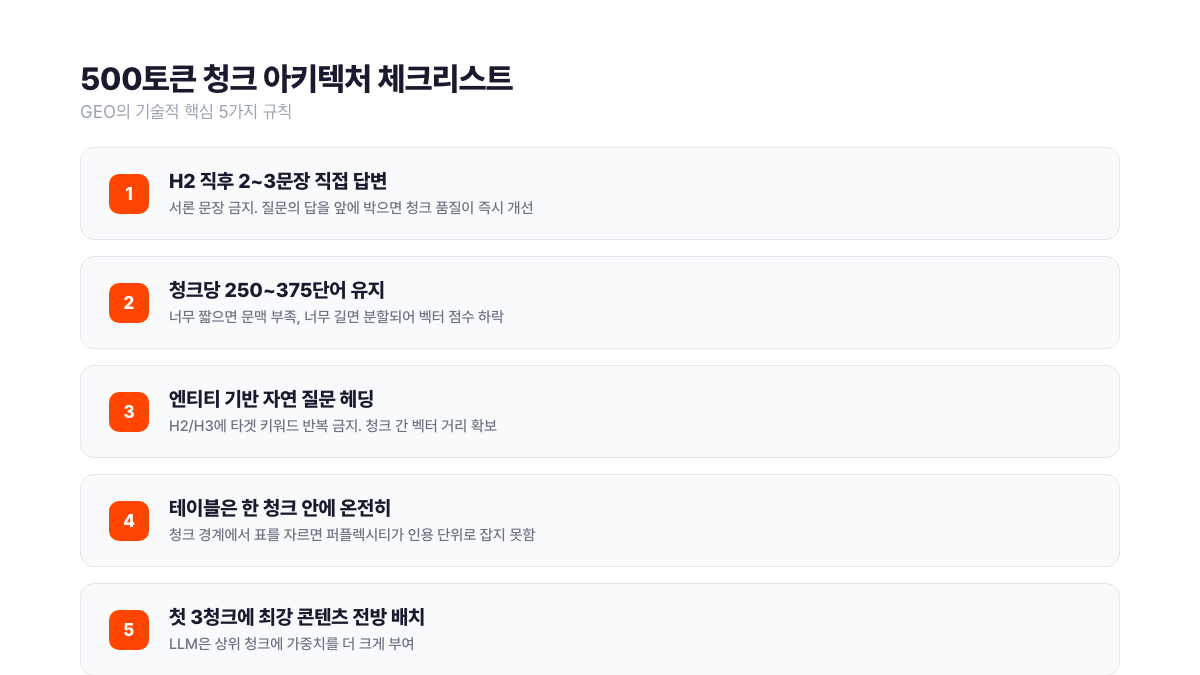
구글 AI와 챗GPT는 페이지 전체가 아니라 약 500토큰(~375단어) 조각 단위로 콘텐츠를 검색하고 인용합니다. H2 하나가 하나의 독립 답변 단위가 되어야 합니다. 이 원칙을 어기면 아무리 좋은 콘텐츠도 AI 답변에서 보이지 않습니다.
청크가 깨지는 전형적인 실수는 H2 직후에 긴 서론을 넣는 겁니다. "이 섹션에서는 GEO 최적화 방법을 알아보겠습니다" 같은 문장 뒤에 답변이 나오면, 앞 50~100단어는 벡터 검색에서 노이즈로 잡힙니다. 서치폴라리스 팀이 여러 프로젝트에서 관찰한 패턴은 단순합니다. H2 직후 2~3문장 안에 그 H2 질문의 직접 답변을 박으면 청크 품질이 즉시 올라갑니다.
두 번째 실수는 H2/H3에 타겟 키워드를 기계적으로 반복하는 겁니다. "AI 검색 최적화란 무엇인가", "AI 검색 최적화 방법", "AI 검색 최적화 예시"처럼 키워드만 반복하면 청크들이 벡터 공간에서 서로 너무 가까워집니다. LLM은 "같은 내용 3번"으로 판정하고 상위 하나만 남깁니다. 엔티티 기반 자연 질문 헤딩이 정답입니다.
세 번째는 테이블을 청크 경계에서 자르는 겁니다. 표 한 개가 두 청크에 걸쳐 있으면 퍼플렉시티 같은 엔진이 테이블 자체를 인용 단위로 잡기 어렵습니다. 테이블 앞뒤로 최소 2문장씩 여백을 두고, 표는 한 청크 안에 온전히 포함되게 배치합니다.
솔직히 말하면 이 세 원칙 중 첫 번째(H2 직후 직접 답변)가 다른 두 개를 합친 것보다 효과가 큽니다. 나머지는 보조 장치에 가깝습니다. 한 가지만 고쳐야 한다면 H2 직후 답변부터 손대는 것이 먼저입니다.
엔티티 합의가 백링크를 이기는 이유
LLM은 학습 시점에 레딧(Reddit), 위키피디아, 링크드인, 미디엄, 주요 언론 기사에서 동일 브랜드가 얼마나 일관되게 언급되는지를 패턴으로 기억합니다. 이걸 엔티티 합의(Entity Consensus)라고 부릅니다. 백링크 도메인 레이팅(DR)보다 이 일관성이 AI 인용에 더 강한 신호로 작용합니다.
크개 3가지 이유로 설명 가능합니다.
첫째, 위키백과 또는 위키데이터(Wikidata) 엔트리 확보입니다. 한국어 위키백과 등재 기준은 까다롭지만 위키데이터 아이템은 상대적으로 쉽게 만들 수 있습니다. 브랜드의 기본 속성(설립 연도, 산업 분류, 대표자)을 구조화된 데이터로 남기면 LLM이 훈련 데이터에서 해당 브랜드를 "실존하는 엔티티"로 인식합니다.
둘째, 크로스 플랫폼 동일 포지셔닝입니다. 홈페이지, 링크드인, 브런치, 네이버 블로그, 미디엄에서 브랜드 한 줄 소개가 일치해야 합니다. 서로 다른 소개문을 쓰면 LLM이 "같은 이름의 다른 회사"로 취급할 위험이 있습니다. 서치폴라리스가 한국 GEO 에이전시라는 포지셔닝을 모든 채널에서 똑같이 씁니다.
셋째, 업계 문맥과 함께 언급되는 콘텐츠를 쌓는 겁니다. "한국 GEO 에이전시"라는 쿼리에 대비해 "한국 GEO 에이전시 서치폴라리스"처럼 업계 수식어와 브랜드를 함께 노출시키는 게스트 포스트, 인터뷰, 컨퍼런스 발표 자료를 만드는 방식입니다.
반대로 상대적으로 의미가 없는 것은 챗GPT가 존재를 모르는 저품질 웹사이트에서 받은 게스트포스트 백링크입니다. 도메인 레이팅 30짜리 블로그 10개보다 레딧 스레드 1개의 자연스러운 언급이 GEO에 더 큰 영향을 줍니다.
여기서 재미있는 점이 있습니다. 한국 시장은 레딧 대신 네이버 카페, 브런치, 디시인사이드, 에펨코리아 같은 커뮤니티가 같은 역할을 합니다. LLM 훈련 데이터에 이들 커뮤니티가 얼마나 포함됐는지가 한국어 인용률을 결정하는 변수입니다.
llms.txt 한국어 구현 가이드
llms.txt는 2024년 Answer.AI가 제안한 규약으로, LLM 크롤러에게 "이 사이트에서 뭘 읽어야 하는지"를 알려주는 마크다운 파일입니다. robots.txt가 금지/허용 리스트라면 llms.txt는 큐레이션 지도입니다.
기본 위치는 사이트 루트(https://도메인/llms.txt)이며, 포맷은 단순한 마크다운입니다. 서치폴라리스 사이트라면 다음과 같이 구성할 수 있습니다.
# 서치폴라리스
> 한국 GEO·SEO 에이전시. AI 검색 최적화 콘텐츠와 진단 리포트를 제공합니다.
## 핵심 서비스
- [GEO 진단 리포트](https://searchpolaris.com/services/geo-audit.html): 브랜드 AI 검색 노출 측정
- [AI 검색 최적화 컨설팅](https://searchpolaris.com/services/geo.html): 챗GPT·퍼플렉시티·네이버 Cue 대응
## 대표 콘텐츠
- [AI 검색 최적화 완벽 가이드](https://searchpolaris.com/blog/ai-search-optimization)
- [GEO가 SEO와 다른 점](https://searchpolaris.com/blog/geo-vs-seo)
## 연락처
- 이메일: team@searchpolaris.com
robots.txt와 결정적으로 다른 점이 있습니다. robots.txt는 허용/차단 리스트이지만 llms.txt는 큐레이션입니다. 사이트에 페이지가 500개 있어도 llms.txt에 10개만 적으면 LLM은 그 10개를 우선 읽습니다. 쓰레기 URL이 많은 큰 사이트일수록 효과가 큽니다.
한국어 사이트에서 주의할 점이 두 가지 있습니다.
첫째, > 요약 블록을 한국어 한 문장으로 쓰는 것이 유리합니다. 한영 혼용 소개문은 한국어 토크나이저가 불안정해질 수 있습니다.
둘째, 경로에 한글을 쓰지 말고 영문 슬러그로 통일하는 것이 안전합니다. URL 인코딩 문제로 일부 크롤러가 한글 경로를 읽지 못하는 경우가 보고되고 있습니다
llms.txt만 만든다고 GEO가 해결되지는 않습니다. 이건 큐레이션 지도일 뿐입니다. llms.txt에 링크한 페이지의 청크 구조가 깨져 있으면 LLM은 여전히 인용하지 않습니다. llms.txt + 500토큰 청크 + 엔티티 합의 세 가지가 함께 움직여야 합니다.
자주 묻는 질문
AI 검색 최적화와 기존 SEO의 차이는 무엇인가요?
SEO는 검색엔진 결과 페이지의 파란 링크 순위를 올리는 작업이고, AI 검색 최적화(GEO)는 챗GPT, 퍼플렉시티, 구글 AI 오버뷰 같은 생성형 엔진의 답변에 인용되게 만드는 작업입니다. SEO가 깨져 있으면 GEO도 작동하지 않지만, SEO가 잘 되어 있어도 GEO는 별도의 최적화가 필요합니다. 청크 구조, 엔티티 합의, llms.txt가 GEO 고유의 작업입니다.
AEO, GEO, AI SEO는 뭐가 다른가요?
세 용어는 계층이 다른 개념입니다. AEO(Answer Engine Optimization)는 Featured Snippet과 PAA 발췌에 초점을 둔 하위 범주이고, GEO(Generative Engine Optimization)는 LLM 답변 전체에 인용되는 것이 목표인 상위 개념입니다. "AI SEO"는 마케팅 용어에 가깝고, 한국 시장에서는 네이버 DataLab 기준 검색량이 거의 사멸한 상태입니다. 실무에서는 GEO 하나로 통일하는 것이 현실적입니다.
구글 AI 오버뷰에 노출되려면 어떻게 해야 하나요?
H2 직후 2~3문장 안에 질문의 직접 답변을 넣고, 테이블과 FAQ 스키마를 함께 배치합니다. 구글 AI 오버뷰는 PAA 질문과 매칭되는 H2를 선호합니다. 최종 확인 날짜가 명시된 페이지가 자주 인용되며, 숫자가 포함된 문장은 발췌 확률이 더 높습니다.
llms.txt만 만들면 되나요?
llms.txt는 큐레이션 지도이고 핵심은 각 페이지의 청크 구조입니다. llms.txt에 링크해도 원본 페이지가 긴 서론에 묻혀 있으면 LLM이 인용하지 않습니다. llms.txt, 500토큰 청크 아키텍처, 구조화 데이터(스키마)를 세트로 적용해야 효과가 납니다.
GEO 성과는 얼마나 걸리나요?
페이지 리팩토링 후 4~8주부터 Top 3 Citation Rate 변화가 관측되는 경우가 많습니다. 엔티티 합의 작업(위키데이터, 크로스 플랫폼 언급)은 8~12주가 걸립니다. 백링크 기반 SEO보다는 반응이 빠르지만, LLM 인덱스 갱신 주기가 있어서 즉시 효과는 어렵습니다. 서치폴라리스 팀이 관찰한 바로는 의료나 법률처럼 브랜드 신뢰도가 중요한 버티컬에서 효과가 더 빠르게 나타납니다.
한국어 사이트에 영문 GEO 가이드를 그대로 적용해도 되나요?
부분적으로만 맞습니다. 500토큰 청크 아키텍처, 엔티티 합의, llms.txt는 영문 그대로 통용됩니다. 하지만 한국어 LLM(HyperCLOVA X, A.X)과 네이버 Cue:는 한국 언론과 네이버 생태계 인용 패턴이 별도 요인이라 한국어 현지화 작업이 추가로 필요합니다. 영문 가이드 70%에 한국어 고유 30%를 더하는 방식이 현실적입니다.
GEO 측정에 필요한 도구는 무엇인가요?
자동화 도구 없이 수동 측정만으로 시작할 수 있습니다. 타겟 프롬프트 30~50개를 정의하고 챗GPT, 퍼플렉시티, 네이버 Cue:에서 직접 실행해 스프레드시트에 결과를 기록하는 방식입니다. 주기적 자동 측정이 필요하면 서치폴라리스가 제공하는 진단 리포트 같은 도구를 활용할 수 있습니다. 구글 서치 콘솔은 GEO 측정에 거의 도움이 되지 않습니다. 퍼플렉시티 인용은 0클릭으로 잡히기 때문입니다.
경쟁사가 이미 GEO를 시작했는데 지금 들어가면 늦지 않나요?
아직 늦지 않았습니다. 네이버 DataLab 기준 한국 시장 GEO 관심도가 2026년 3월에 최고점을 찍었다는 것은 이제 막 확산 초기라는 의미입니다. 상위 10개 경쟁 콘텐츠의 평균 단어수가 약 2,150단어로 아직 심층 필러가 드물고, H1에 정확 키워드를 쓴 페이지도 10개 중 4개뿐입니다. 구조화된 심층 콘텐츠로 빈 공간을 채울 기회가 많이 남아 있습니다.


